Занятие 2. Процесс индексирования
(Продолжительность занятия 45 минут)
Индексирование — это процесс, с помощью которого Index Server составляет каталоги текста и свойств документов, хранящихся на Вашем узле Internet Information Server. На этом занятии описаны все фазы и составляющие процесса индексирования. Кроме того, Вы узнаете, как администрировать Index Server с помощью встраиваемого модуля Index Server Administration консоли управления Microsoft Management Console (MMC).
Изучив материал этого занятия, Вы сможете:
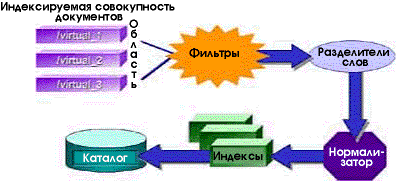
Индексирование — это фоновый процесс, не требующий участия пользователя. Вначале определяется совокупность подлежащих индексированию документов, затем фильтруются содержимое и свойства каждого из них и, наконец, создается каталог, содержащий соответствующий индекс.
Индексируемая совокупность документов
Набор подлежащих индексированию документов на узле Internet Information Server называется индексируемой совокупностью. Вы можете хранить файлы совокупности на одном или нескольких физических носителях на локальной машине или на сетевом сервере; каждую из папок, содержащих нужные файлы, Вам придется сконфигурировать как виртуальный сервер или как виртуальный каталог. Выбирая папки, подлежащие индексированию, Вы тем самым задаете область индексирования.
Примечание Чтобы повысить производительность, разместите данные Index Server на другом диске, отдельно от индексируемых файлов.
Фильтры содержимого
Фильтры содержимого — это программы, позволяющие индексировать файлы различных типов. Обычно документы, созданные конкретным приложением, хранятся в файлах специального формата. Например, формат файлов документов WordPerfect отличается от формата файлов документов Microsoft Word. Для индексирования файлов специальных форматов Index Server использует фильтры содержимого. Фильтры, как следует из их назначения, «умеют»:
Когда фильтр содержимого встречает в документе встроенный объект, он определяет его тип и активизирует соответствующий фильтр. Таким образом, Index Server может индексировать не только текст документа Word, но и любой текст во встроенной в него таблице Microsoft Excel.
Поскольку за обработку всех деталей конкретного файлового формата отвечает фильтр, для индексирования файлов конкретного формата достаточно добавить соответствующий фильтр. Таким образом, Вы легко расширите список форматов, которые поддерживает Index Server.
Разделители слов
Результат работы фильтра содержимого — поток символов, тогда как Index Server индексирует слова. Поэтому, чтобы индексирование выполнялось корректно, Index Server должен уметь выделять слова из потока символов. Эта задача усложняется тем, что в различных языках по-разному трактуют ее слова и разделители слов.
Чтобы справиться с этой задачей, Index Server задействует языково-зависимые программные разделители слов, которые корректно разделяют поток символов на слова. Разделители слов учитывают особенности структуры и синтаксиса конкретного языка для выделения слов из потока символов.
Примечание Во избежание проблем с кодовыми страницами и других трудностей, связанных с однобайтовыми наборами символов, Index Server использует для хранения всех своих индексных данных двухбайтовую кодировку Unicode.
Нормализатор
Нормализатор «причесывает» поток слов, поступающий от разделителя, выполняя такие функции, как перевод всех символов в один и тот же регистр, удаление знаков пунктуации и удаление неинформативных слов.
В большинстве языков письменный текст содержит достаточно много неинформативных слов. В английском языке, например, это «the», «of», «and», «you» и около сотни других. По очевидным причинам, такие слова нет смысла включать в индекс. Для каждого из поддерживаемых языков Index Server располагает общесистемным списком неинформативных слов, который Вы можете настроить с учетом местного диалекта и терминов. Когда разделитель слов во время анализа потока символов обнаруживает неинформативное слово, нормализатор обеспечивает его пропуск при индексировании. Так как неинформативные слова составляют большую часть письменного текста, их удаление может значительно уменьшить размер результирующего индекса.
Только после того, как поток слов нормализован, Index Server включает слова в индекс.
Индексы
Index Server поддерживает индексы двух видов: словари и постоянные индексы. Слова и свойства, вьделенные из документа, сначала заносятся в словарь, а затем — в постоянный индекс. Такая организация позволяет улучшить обработку запросов и повысить производительность, а также обеспечивает оптимальное использование ресурсов. Даже если Index Server работает с несколькими индексами, эти подробности полностью скрыты от пользователя: пользователь видит лишь список документов, отвечающих сформулированному им запросу.
Словари
Словари — это небольшие временные индексы, хранящиеся в памяти. Каждый словарь содержит сведения о нескольких документах. Когда Index Server фильтрует документ, он сохраняет данные в словаре. Создание словарей занимает очень мало времени и не требует обновления информации на жестком диске. Словари выполняет роль области промежуточного хранения данных при индексировании.
Для управления поведением словарей можно воспользоваться ключами реестра, которые находятся в разделе \HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Content Index
В приведенной ниже таблице перечислены ключи реестра, относящиеся к словарям, и их описание.
| Параметр |
|
| MaxWordLists |
|
| MaxWordlistSize |
|
| MinSizeMerdgeWordlists |
|
| MinWordlistMemory |
|
Когда число словарей превосходит значение параметра MaxWordLists, Index Server объединяет их в промежуточный индекс с помощью процесса, называемого промежуточным слиянием (Вы познакомитесь с ним позже на этом занятии). Хотя при хранении слов в словаре применяется сжатие данных, оно не слишком эффективно, поскольку словари — всего лишь временные структуры. Кроме того, поскольку словари хранятся в памяти, документы, на основе которых они построены, придется фильтровать заново при следующем запуске Internet Information Server. Index Server самостоятельно определяет, когда необходимо повторное фильтрование, и выполняет его автоматически.
Постоянные индексы
Индекс, хранящийся на жестком диске, называется постоянным. В отличие от словарей, постоянные индексы нечувствительны к отключениям и перезагрузкам системы. Так как данные постоянных индексов хранятся на жестком диске, Index Server эффективно сжимает их. Постоянный индекс бывает либо промежуточным, либо основным.
Промежуточный индекс создается путем слияния словарей и иногда других промежуточных индексов. Каталоги могут содержать несколько промежуточных индексов. Index Server использует промежуточные индексы в качестве временных областей хранения данных, предназначенных для слияния в основной индекс. Применение промежуточных индексов позволяет поддерживать актуальность индексов без выполнения ресурсоемких операций. Однако в силу того, что промежуточные индексы сжаты не так сильно, как основные, они занимают больший объем на жестком диске.
Основной индекс содержит индексные данные для множества документов. Обычно это самая большая постоянная структура данных. Основной' индекс содержит все данные, которые уже проиндексированы на момент его создания. Для основных индексов используются гораздо более мощные средства сжатия, чем для промежуточных. Это обеспечивает значительную степень сжатия данных, однако такие средства требуют для своей работы больше ресурсов.
Index Server создает основной индекс с помощью одноименного процесса слияния, который объединяет все промежуточные и текущий основной индекс (если таковой имеется) в новый основной индекс. По завершении слияния Index Server удаляет все исходные индексы, оставляя только новый основной индекс. После этого запросы обслуживаются с максимальной эффективностью. Процесс создания основного индекса описан ниже в этой главе.
Общее число постоянных индексов (как промежуточных, так и основных) в любом каталоге не может превышать 255.
Каталоги
Каталог — это высший организационный уровень иерархии данных Index Server. Каждый каталог является полностью автономной единицей, содержащей индекс и кэшированные списки свойств для одной или нескольких областей данных (виртуальных серверов). Запросы Index Server не могут охватывать несколько каталогов.
Каталог по умолчанию
Исходное местонахождение каталога, заданное во время установки, хранится в элементе реестра IsapiDefaultCatalogDirectory. Этот каталог используется, пока Вы не укажете другой каталог в .idq—файле. Каталог по умолчанию содержит индекс всех виртуальных серверов, к которым разрешен доступ на чтение. Область, охватываемая каталогом, задается административными средствами.
Создание нескольких каталогов
Вы можете создать несколько каталогов для распределения запросов и поддержки виртуальных серверов.
Поскольку Index Server не поддерживает запросы, охватывающие более одного каталога, Вам следует продумать возможные последствия создания нескольких каталогов. Увеличение их числа приведет к невозможности охватить все содержимое узла Internet Information Server одним запросом; кроме того, наличие нескольких каталогов осложняет стандартную поддержку каталога.
Распределение нескольких физических серверов по нескольким каталогам повышает производительность запросов, но только в том случае, когда большинство запросов ограничено подобластью (одним или несколькими физическими серверами) Web-узла. Повышение производительности в этом случае обусловлено снижением числа ложных ответов со ссылками на документы, расположенные за пределами интересующей Вас области.
Процесс CiDaemon
Это дочерний процесс, порождаемый ядром индексирования Index Server. Ядро индексирования передает этому процессу список документов, а процесс CiDaemon отвечает за фильтрование документов и, в частности, за поиск необходимых динамических библиотек фильтра и разделителя слов для каждого конкретного документа.
Фильтрование выполняется в фоновом режиме, чтобы не мешать основным операциям. Если документ, открытый процессом CiDaemon на локальном жестком диске, требуется другому процессу для записи, то процесс CiDaemon откладывает его фильтрование и закрывает документ так быстро, насколько это возможно. Для совместно используемых сетевых папок такой вариант невозможен.
Если процесс CiDaemon завершается. Index Server автоматически перезапускает его.
Типы слияния
Слияние — это процесс объединения нескольких индексов в один. Слияние уменьшает объем избыточных данных и освобождает системные ресурсы. Кроме того, Index Server обслуживает запросы тем быстрее, чем меньше существует индексов.
Возможны три типа операций слияния:
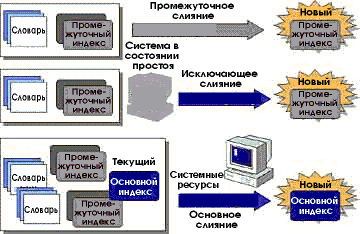
После завершения слияния вместо нескольких исходных индексов формируется один результирующий.
Промежуточное слияние
При промежуточном слиянии несколько словарей и промежуточных индексов объединяются в один промежуточный индекс. Index Server выполняет промежуточное слияние для освобождения памяти, используемой для хранения словарей, и чтобы зафиксировать результаты фильтрования; обычно эта операция выполняется достаточно быстро.
В роли исходных индексов для операции промежуточного слияния чаще всего выступают словари. Однако если общее число постоянных индексов превышает максимальное значение, заданное ключом реестра MaxIndexes (по умолчанию — 50), промежуточному слияния подлежат и промежуточные индексы. Процесс промежуточного слияния автоматически запускается при выполнении хотя бы одного из перечисленных ниже условий:
Исключающее слияние
Это разновидность промежуточного слияния, которая выполняется, только если система находится в состоянии простоя, а общее число постоянных индексов превышает значение, заданное в ключе реестра MaxIdlelndexes. Ключ реестра MinMergeIdleTime задает пороговое значение неиспользуемого объема процессорного времени (в процентах), по достижении которого активизируется процесс исключающего слияния. Эта операция повышает эффективность обслуживания запросов и использования жесткого диска, уменьшая число промежуточных индексов, образованных из словарей.
Основное слияние
Исходные данные этой операции — текущие промежуточные индексы и основной индекс (если таковой имеется). По завершении операции основного слияния Index Server заменяет все исходные индексы одним результирующим основным индексом. Хотя само по себе основное слияние — чрезвычайно ресурсоемкая операция (как для процессора, так и для жесткого диска), в результате ее выполнения освобождаются системные ресурсы и уничтожаются избыточные данные, что резко повышает эффективность обслуживания запросов.
Примечание Если совокупный размер исходных индексов велик, основное слияние может выполняться довольно долго. При возникновении сбоев в работе системы или ее отключении эту операцию можно запустить повторно — после перезапуска выполнение основного слияния продолжится с того места, на котором оно было прервано.
Запуск, перезапуск и приостановка выполнения основного слияния регистрируются в журнале событий.
Выполнение операций основного слияния управляется несколькими ключами реестра.
Кроме того, Вы имеете право принудительно запустить операцию основного слияния, используя административную Web-страницу http://имя_к.омпьютеpa/srchadm/admin.htm). Основное слияние повышает эффективность обслуживания запросов, поэтому можно и не дожидаться, пока будет выполнено одно из описанных выше условий.
Index Server Manager
Интегрируемый модуль Index Server Administration консоли управления Microsoft Management Console предлагает Вам семь инструментальных средств для администрирования Index Server.
Проверка состояния
Средствами интегрируемого модуля Index Server Вы можете выяснить текущее состояние выполнения задач индексирования, а также посмотреть свойства индексируемых папок и кэша свойств документов. Выделив папку Index Server в в левой панели окна Microsoft Management Console, в правой Вы увидите число индексированных файлов, размер каталога, список документов, подлежащих фильтрованию, а также другую информацию.
Установка глобальных свойств
На уровне Index Server можно настроить свойства для всех каталогов — например, отключить создание описаний. В этом случае для файлов, перечисленных на странице результатов поиска, не будут создаваться аннотации. В Вашей воле также изменить значение для конкретного каталога. Значения, установленные на уровне каталога, отменяют значения, заданные на уровне Index Server.
Создание и конфигурирование каталогов
Во время установки Index Server создает каталог Web. Вы можете создавать дополнительные каталоги, а также распределить индексные данные по нескольким каталогам.
Параметры кэша свойств
Чтобы уменьшить время выборки информации для часто используемых запросов, добавьте свойства в кэш на своем сервере. Если свойства не кэшируются, Index Server при каждом запросе будет обращаться непосредственно к документам АсtiveX (например, к документам Microsoft Office), входящим в результате запроса, и извлекать их свойства. В кэш свойств можно добавить и свойства, которые не индексируются по умолчанию, — например, добавив в кэш свойство, соответствующее тэгу META="ServerProduct" VАLUE="название продукта", и снабдив этим тэгом HTML-документы, Вы обеспечите возможность поиска серверных продуктов по названию.
Примечание Если Ваш индекс был поврежден и его приходится создавать заново, Вам придется возобновить и кэш свойств.
Добавление и удаление папок
Средствами интегрируемого модуля Index Server можно добавлять и удалять папки, подлежащие индексированию. Эта операция не затрагивает физические папки, а только лишь инструктирует Index Server, что их нужно включить (или исключить) из списка папок, подлежащих индексированию.
Принудительное сканирование
Для повторного обзора виртуального корневого каталога необходимо выполнить его повторное сканирование. Эта операция необходима после глобальных изменений, например:
> Выполнение принудительного сканирования
Принудительное слияние
Если время обслуживания запросов начинает увеличиваться. Вы можете освободить ресурсы, объединив индексы. Время от времени мелкие индексы следует объединять в более крупные, что позволяет освободить место (как в памяти, так и на диске) и ускорить обработку запросов. Для этого необходимо выполнить операцию принудительного слияния.
> Выполнение принудительного слияния
Резюме
В процессе индексирования Index Server составляет каталог содержимого и свойств документов, хранящихся на Вашем узле Internet Information Server. Процесс начинается с применения фильтров для извлечения потока символов из совокупности документов Вашего узла. С помощью операций слияния индексов полученные словари комбинируются в промежуточные индексы, которые затем объединяются в основной индекс каталога. В состав интегрируемого модуля Index Server Manager входят семь полезных инструментальных средств для администрирования Index Server.